
Elo, explained
An introduction to the model underneath a lot of fight pricing and prediction

A fundamental part of how bookies make lines, and how models like ours give predictions, is the Elo model.
That does not mean sportsbooks use Elo on its own. They do not. And neither should anyone serious. But Elo is one of the cleanest starting points for turning a long fight history into a matchup probability.
The best way to think about Elo is as a running placement system. It tracks where each fighter currently sits in the competitive order implied by the results we have already seen.
When Elo gives a fighter a high rating, it is saying something more specific:
based on the wins and losses in the dataset so far,
adjusted for who those results came against,
this fighter currently projects better than most of the pool
So when the model looks at a matchup, it is really asking four questions:
Where does Fighter A currently sit in that pecking order?
Where does Fighter B currently sit?
Given that gap, what win probability falls out?
After the result comes in, how much new information did we just learn?
That is the whole machine.
Start with one idea: ratings are just running estimates
In Elo, every fighter carries a rating. Most systems start everyone at the same baseline, often something like 1500, and then let the results move the numbers over time.
The rating is not the destination. The rating is the input. The thing we actually want is a probability, and Figure 1 gives a few easy anchor points for that conversion.
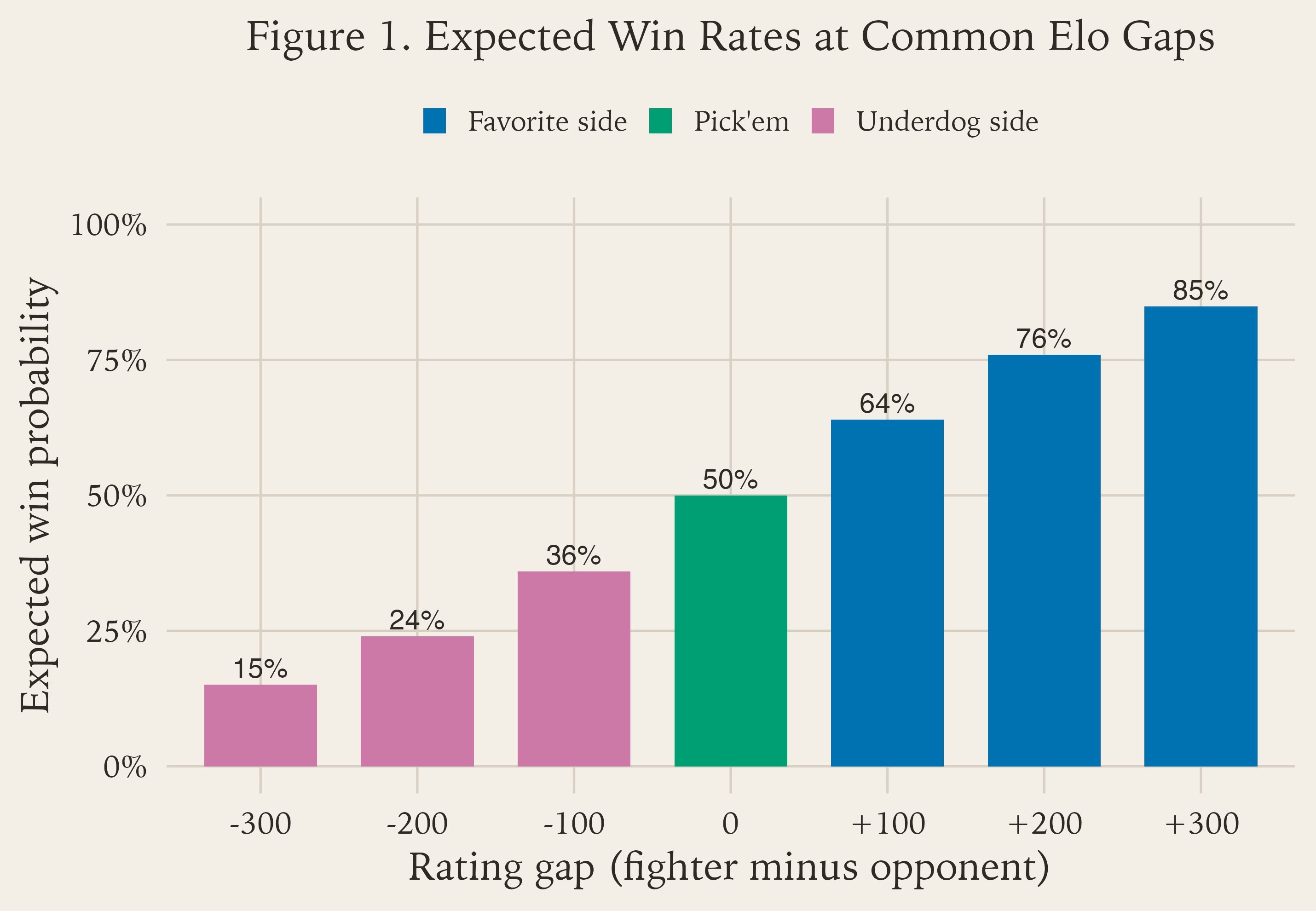
As Figure 1 shows, equal ratings produce something close to a coin flip. Once one fighter’s rating moves ahead, the model starts expecting that fighter to win more often. The larger the gap, the higher the expected win rate.
That is why Elo is so useful. It takes a messy history of fights and compresses it into a number you can immediately turn into a forecast.
Component 1: the rating gap
The first component is just:
rating gap = fighter rating - opponent rating
If Fighter A is 1700 and Fighter B is 1600, the gap is +100. That does not mean Fighter A wins every time. It means the model has seen enough evidence to treat Fighter A as the favorite right now.
That is an important distinction. Elo is not predicting destiny. It is setting a baseline expectation.
Component 2: turn the gap into betting language
Figure 2 is the same logic as Figure 1, just written in the language sportsbooks use.
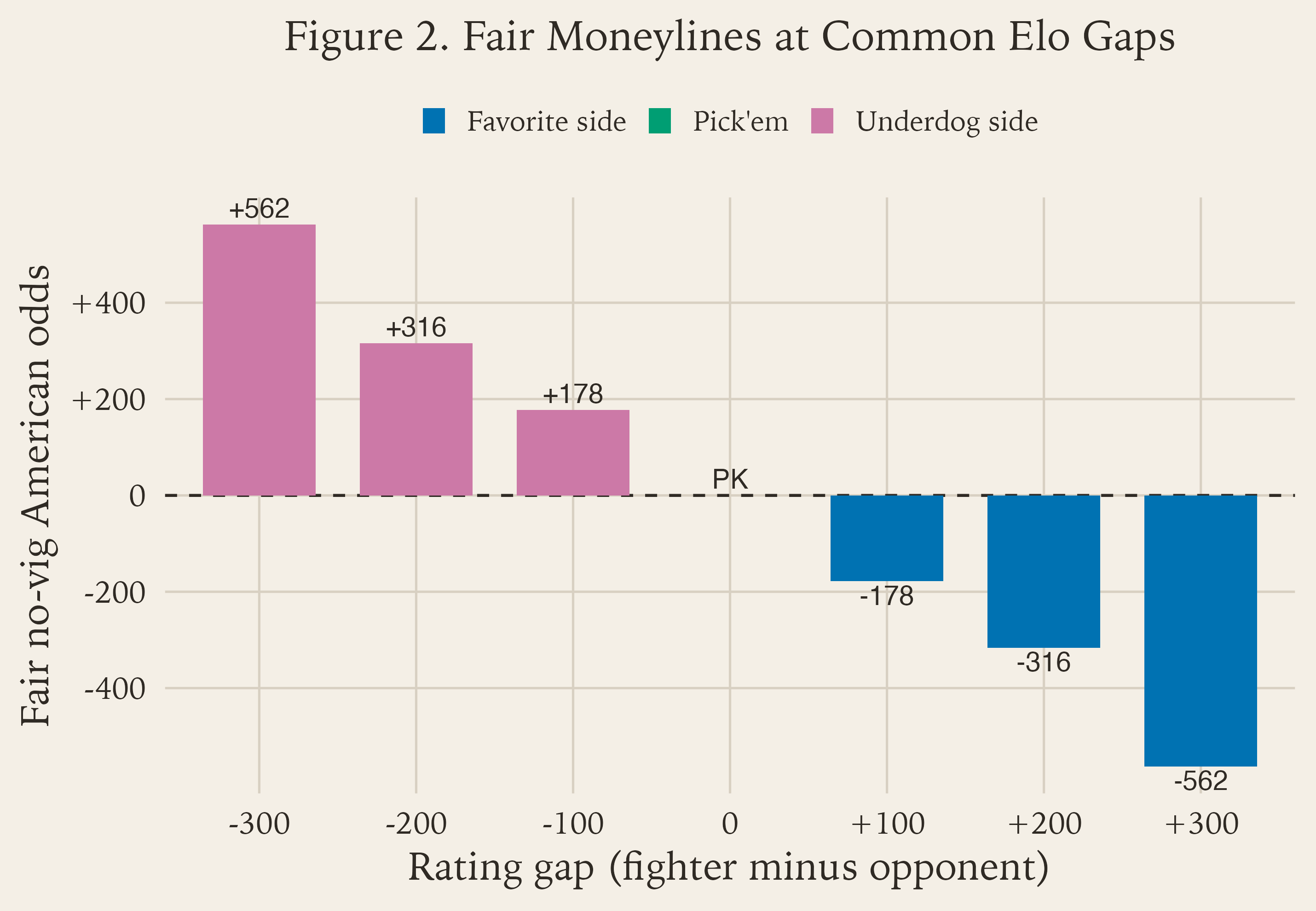
PK is pick’em.For non-stats people, this is the key idea: Figure 2 is not introducing a new model. It is just translating the old one.
If Elo says a fighter should win about 50% of the time, that is basically a pick’em.
If Elo says a fighter should win about 64% of the time, that is the same opinion as a fair line around -180.
If Elo says a fighter should win about 36% of the time, that is the same opinion as a fair line around +180.
That is why Figure 2 matters. Books do not write “64%.” They write -180. So if you want to compare a model to a market, you need a translation layer between probability language and odds language.
The bar chart makes that easier to remember:
the middle bar is
PK, which is just a pick’embars below zero are favorite prices
bars above zero are underdog prices
the farther you move from the middle, the more lopsided the matchup becomes
And one more important point: Figure 2 is fair no-vig pricing. Real sportsbook numbers will usually be a little wider because books add margin and other adjustments. But as a baseline translation tool, this is exactly the bridge you need.
Component 3: Elo updates are about surprise
This is the part most people miss.
After the fight, Elo looks at only one thing:
actual result - expected result
If you were supposed to win and you won, the model updates you only a little.
If you were supposed to lose and you won anyway, the model says: that was surprising, we need to move ratings more.
Figure 3 makes that idea concrete with one 200 -point matchup shown four different ways.
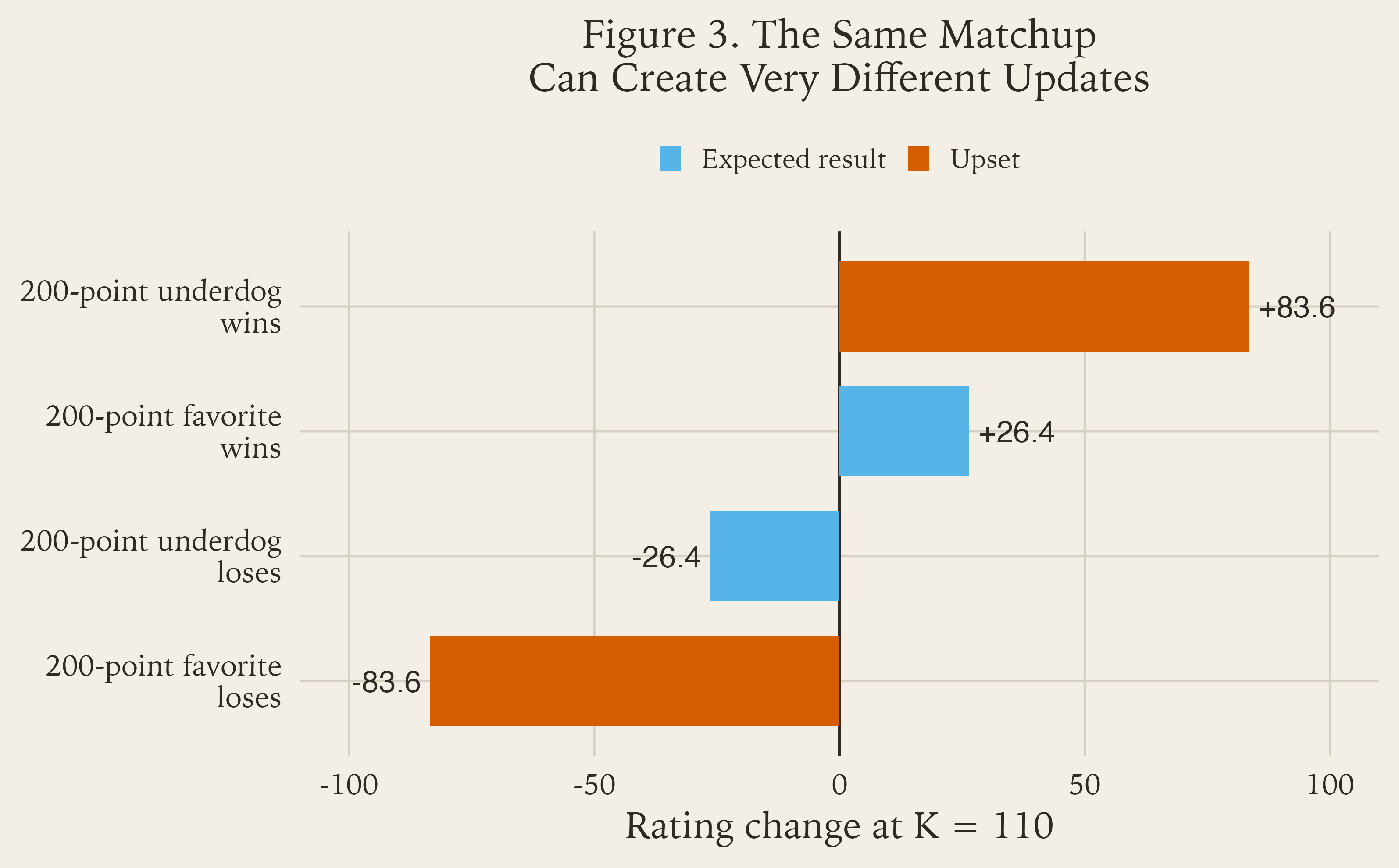
200-point matchup at K = 110, expected results create smaller moves and upsets create larger ones.The cleanest way to read Figure 3 is this:
when you were already a big favorite, winning does not tell the model much it did not already believe
when you were already a big favorite, losing tells the model it was badly overconfident
when you were a big underdog, losing is not very informative
when you were a big underdog and still won, the model has to adjust sharply
So Elo is not “rewarding wins.” It is rewarding information. Here, “information” means evidence that should change the model’s belief about the fighters.
If the model thought a fighter was very likely to win and that fighter won, then most of the result was already baked into the forecast. Very little new was learned, so the update stays small.
If the model thought a fighter was unlikely to win and that fighter won anyway, that result is packed with new information. The model has just learned that its old estimate was off, so the update is much larger.
That asymmetry is the whole logic of Elo updating.
A 200-point favorite winning is basically the model saying, “that is more or less what I expected.” So the update is modest.
A 200-point favorite losing is the opposite. The model has just been told, very directly, that its pre-fight belief was wrong. That is why the rating drop is much larger.
This is also why Elo stays intuitive even for people who do not care about formulas. It reacts the way a reasonable observer would react:
expected result -> mild update
surprising result -> strong update
Component 4: the K-factor
The K factor is the speed knob. Figure 4 shows what that means with the exact same upset held constant.
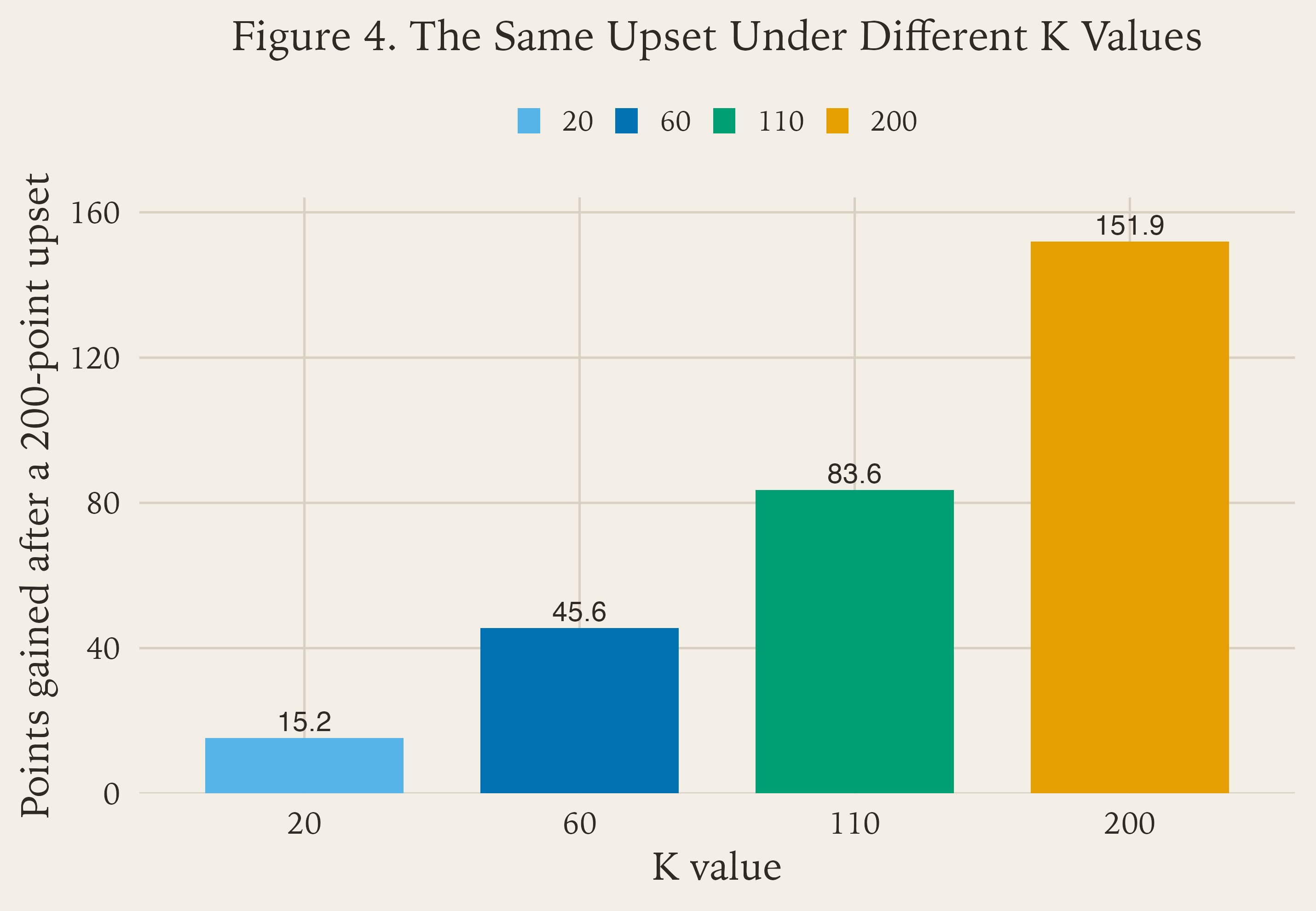
K = 20, 60, 110, 200.Low K means the model is cautious. It updates slowly and trusts the long run.
High K means the model is reactive. It updates quickly and treats each result as more informative.
That tradeoff matters in MMA because fighters are not static:
camps change
weight cuts matter
age cliffs happen fast
style matchups are real
layoffs can scramble form
If K is too low, the model can stay stale. If K is too high, it can overreact to noise. That is why we tune it instead of guessing.
Component 5: why a fighter’s Elo changes over time
Figure 5 is the part that makes chronology clear.
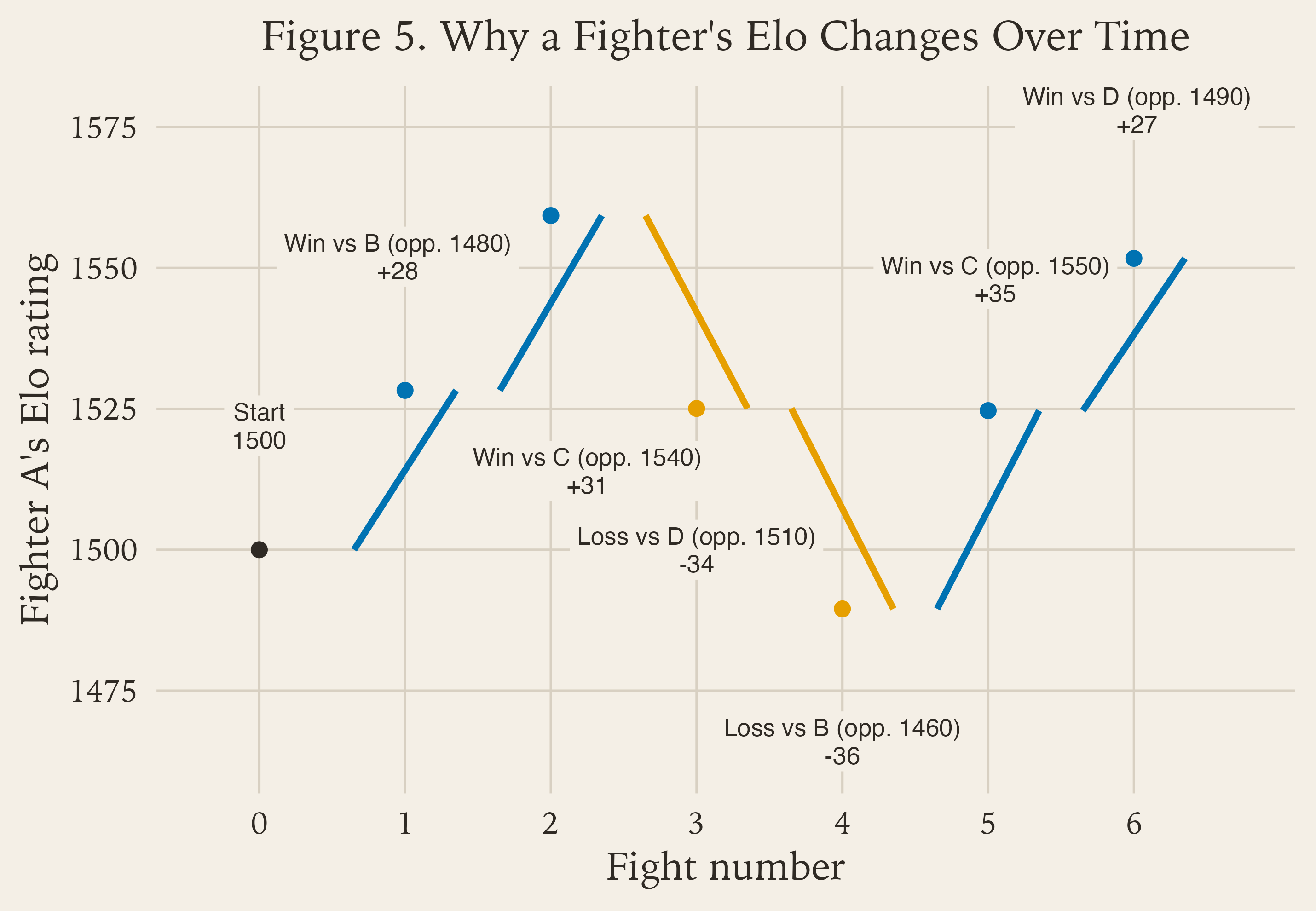
Fight 1: Fighter A beats a slightly lower-rated opponent, so the rating goes up, but only by a modest amount.
Fight 2: Fighter A beats a slightly higher-rated opponent, so the jump is larger.
Fight 3: Fighter A loses to a roughly similar opponent, so the rating drops meaningfully.
Fight 4: Fighter A loses to a lower-rated opponent, so the drop is even harsher.
Fight 5: Fighter A beats a higher-rated opponent, so the model gives back a large chunk of the lost ground.
Fight 6: Fighter A beats a lower-rated opponent, so the final bump is positive but smaller.
This is a toy example, but it shows the mechanism clearly.
Fighter A starts at 1500. After each fight, the rating moves up or down based on two things:
1. did the fighter win or lose?
2. how hard should that result have been to get, given the opponent’s rating at the time?
That second part is the important one. Beating a higher-rated opponent usually creates a larger jump. Losing to a lower-rated opponent usually creates a larger drop. More routine results create smaller nudges.
So a fighter’s Elo changes over time because each fight resets the starting point for the next one. The rating after fight 3 becomes the rating before fight 4. That is why Elo is path-dependent and why recent results can matter so much in a live rating system.
What a real MMA rating pool looks like
Once you run this over a full fight database, you get a real spread of ratings rather than one flat pile around the starting value. Figure 6 shows that for a baseline `K = 110` Elo run.
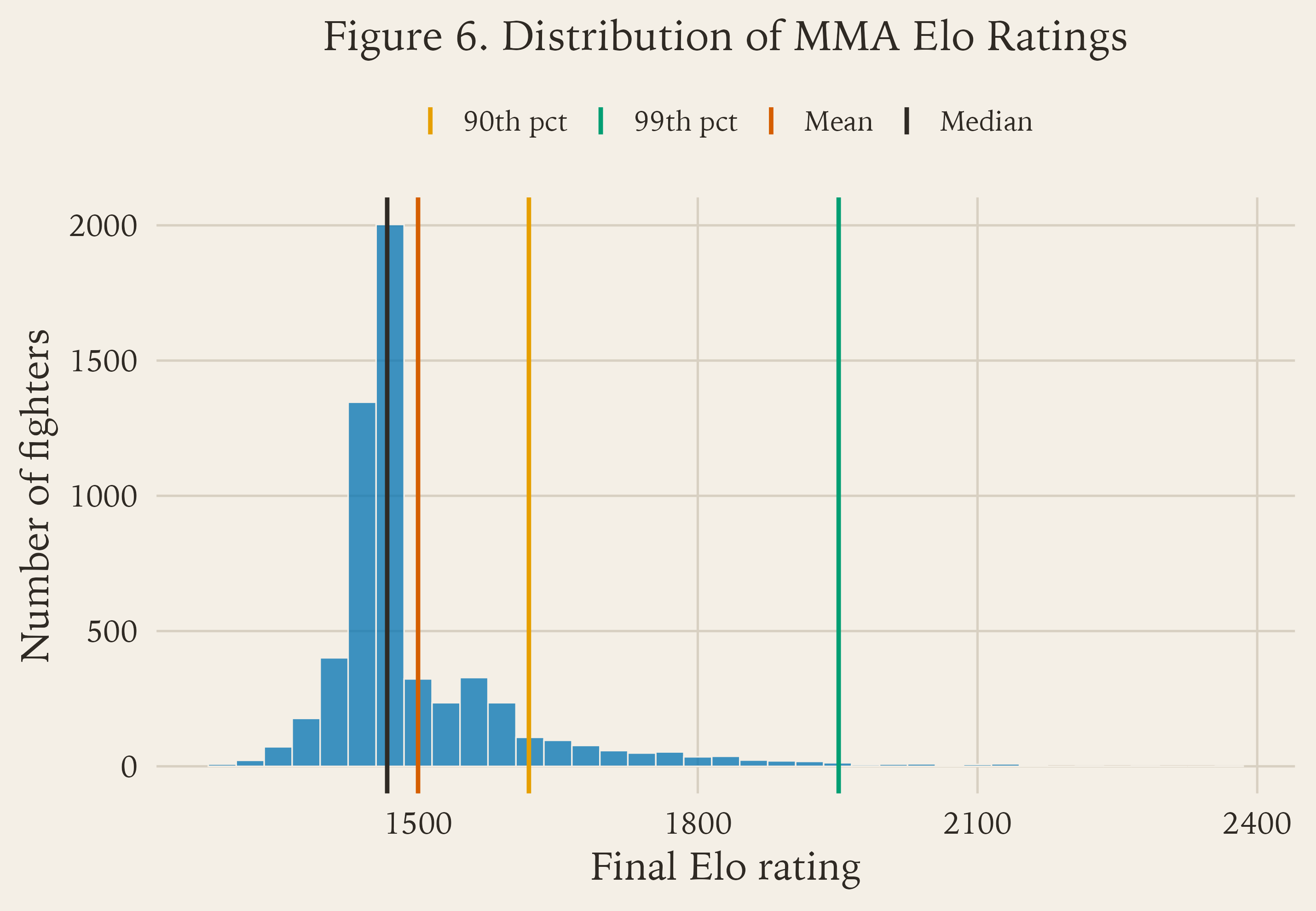
K = 110 Elo run.As Figure 6 shows, most fighters cluster in the middle, with the distribution tapering gradually as you move toward the top end. That is what you would expect in a sport like MMA, where most fighters have mixed records or limited sample sizes, while only a smaller group builds the kind of sustained result profile needed to separate clearly from the pack.
The shape also tells you something important about Elo itself: it does not scatter fighters evenly across the scale. It compresses most of the pool into a broad middle and reserves the far right tail for fighters whose records consistently beat what the model expected over long stretches.
Why this matters for MMA Fight Advisor
Elo matters to MMA Fight Advisor because it gives us a disciplined baseline to compare against.
It is the piece that says: given the total fight-history record, before we start talking about style, camp changes, injuries, or market movement, what win probability does this matchup deserve?
That matters for three reasons:
it keeps the model grounded in a consistent historical baseline
it helps us avoid making every prediction a one-off vibe check
it gives us a clean number to compare against the market
Right now, that is how we use it: as a comparison point against our proprietary model. The point is not that Elo is part of the engine. The point is that it gives us a stable benchmark, and our proprietary model is doing much better than a plain Elo approach.
From there, we can layer on the things Elo does not know on its own:
stylistic matchup details
physical traits
short-notice context
recent form signals
market information
So, Elo is not part of the current MMA Fight Advisor engine. It is a benchmark model that helps us measure whether the proprietary model is actually adding forecasting value beyond a simple, disciplined baseline.
Bottom line
Elo is not magic. It is just a disciplined way to do four things:
1. place each fighter inside a running competitive order
2. convert the gap between two fighters into a win probability
3. react more to surprises than to routine outcomes
4. carry that updated information forward into the next fight
That is simple enough to explain in one article, but powerful enough that some version of it still sits underneath a huge amount of sports pricing and prediction work.
If you understand those four steps, you understand the core engine.
That's very similar to how chess players are rated if not actually the same model.
FIGHTS.IO