
The Brier score is what accuracy wishes it were
A 1950 weather-forecast metric that still does a better job grading probabilities than most sports conversations do

Two analysts call a fight. One says the favorite wins 51% of the time. The other says 90%. The favorite wins.
By the stat most sports media still leans on, those two analysts just tied.
But if you are a fan trying to figure out who to trust, those are obviously not the same forecast. One said, “this is basically a coin flip.” The other said, “this should almost never lose.” Accuracy cannot tell them apart.
That is the problem this article is about, and the reason a metric built for weather in 1950 still happens to be one of the cleanest tools we have for grading any sports model that publishes probabilities.
It is also the lens I want MMA Fight Advisor to use on its own work: not just “did we pick the side,” but “did our confidence level deserve to be trusted?”
The one-line definition
For a binary event, meaning a simple yes-or-no outcome, the single-forecast Brier score is:
where:
pis the predicted probability that the event happensyis1if it happens and0if it does not
In plain English: take the gap between what you predicted and what actually happened, square it, and average that across all your forecasts. That is it. The math is one line because the idea is one line.
Lower is better.
Three anchors make the scale intuitive right away:
0.00= perfect0.25= what you get by saying50%every time1.00= certainty in the wrong direction
A bit of history
The score is named after Glenn W. Brier, a meteorologist who introduced it in 1950 while evaluating weather forecasts stated in probabilities.
That origin matters. Weather forecasters were not just asking, “Did it rain?” They were asking, “When we said 30%, 60%, or 90%, did those numbers actually mean what we claimed they meant?”
Sports models have exactly the same problem.
If your model says a favorite wins 58% of the time, that is not just a pick. It is a probability claim. The Brier score exists to grade that claim.
Four tiny examples that explain almost everything

That table is the whole argument in miniature.
Accuracy sees only two buckets: correct and wrong.
Brier sees something much more human:
A narrow lean is not the same thing as a conviction pick
A small miss is not the same thing as a catastrophic overconfident miss
Confidence should be rewarded only when it is deserved
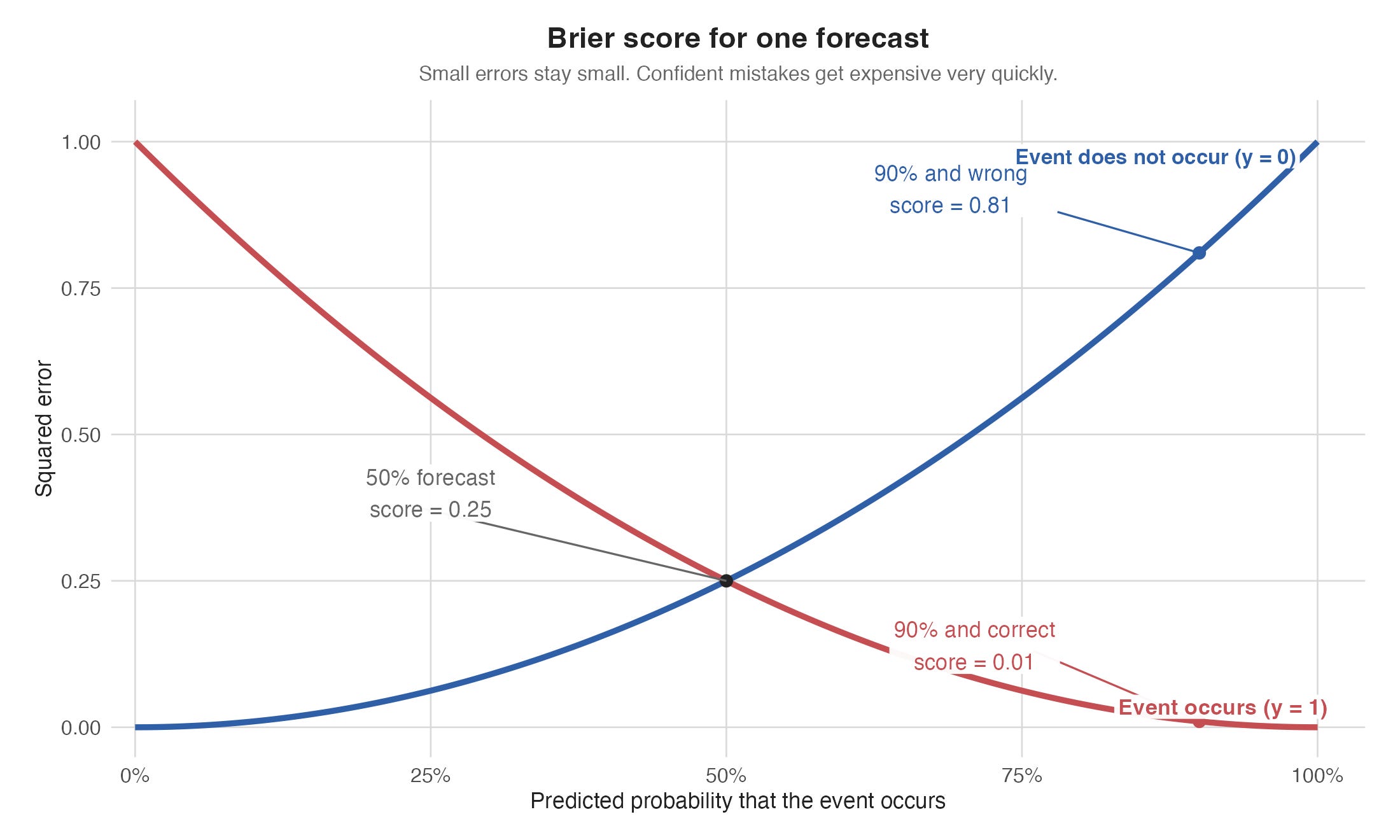
Why Brier is better than accuracy
If you are publishing hard picks, accuracy is fine. If you are publishing probabilities, accuracy is grading the wrong thing.
Accuracy treats these as identical:
- “I think this side wins 51% of the time.”
- “I think this side wins 90% of the time.”
But those are wildly different statements. One says “coin flip with a lean.” The other says “this should almost always cash.” If both happen to win once, accuracy calls it a tie. Brier does not.
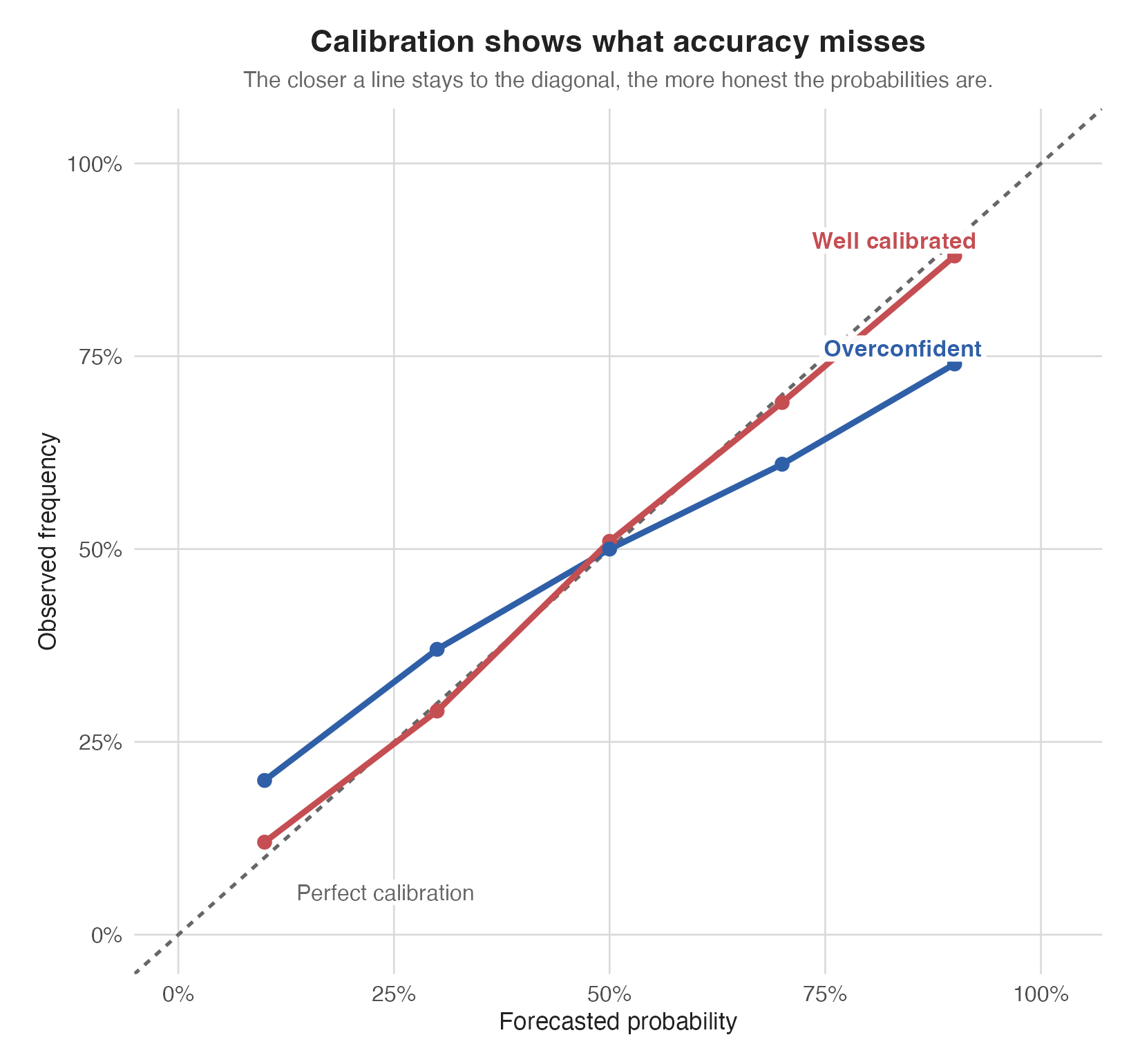
Even better, Brier does not just reward caution. It rewards honesty.
If you are really right about 70% of the time, the best long-run number to report is about 70%, not 55% and not 90%x.
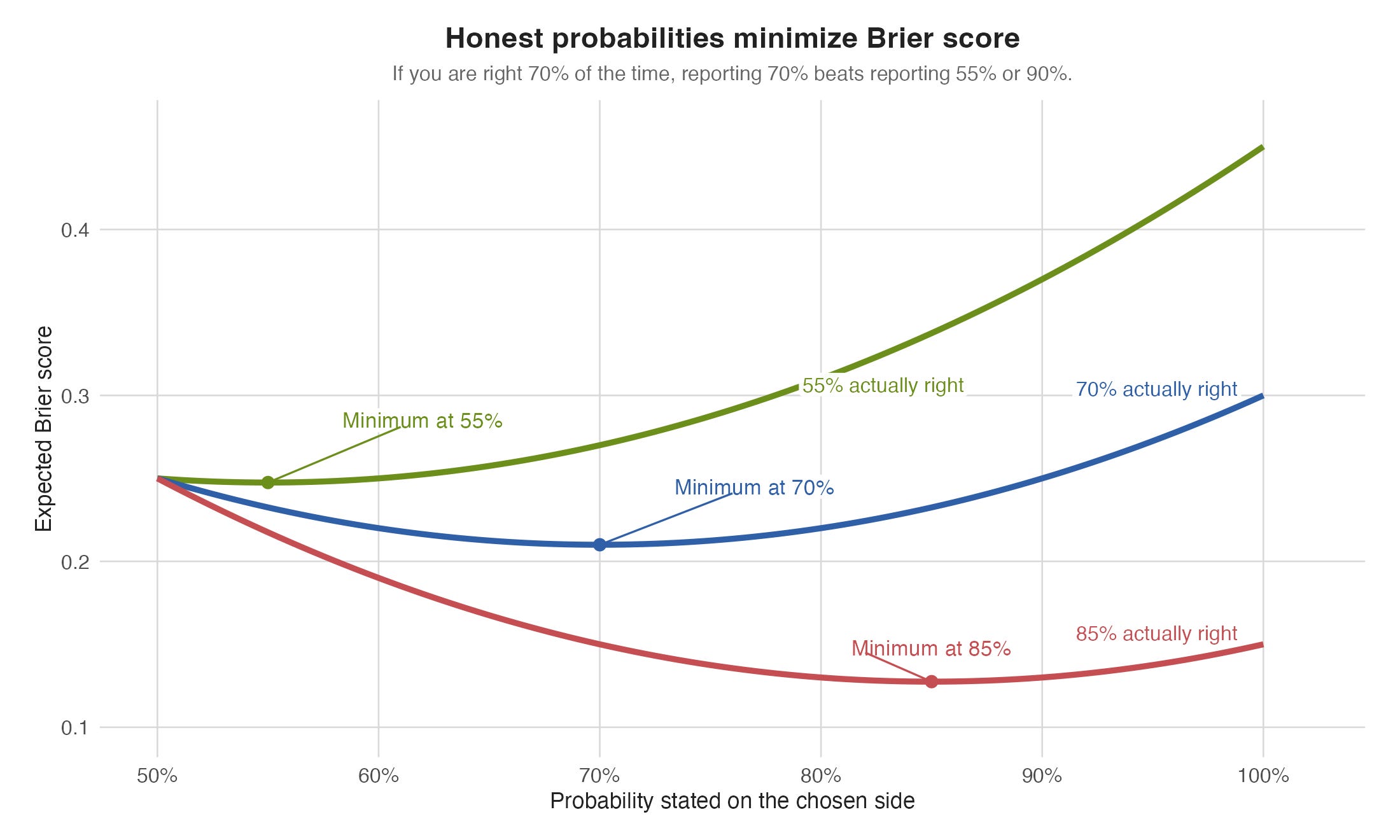
Put even more plainly: if you really are right 70% of the time, saying 70% beats pretending 55% or 90%. That is the whole chart.
That is one of the elegant things about the metric: it quietly pressures you to be calibrated. Inflate your probabilities and you get punished. Sandbag them too much and you also leave score on the table.
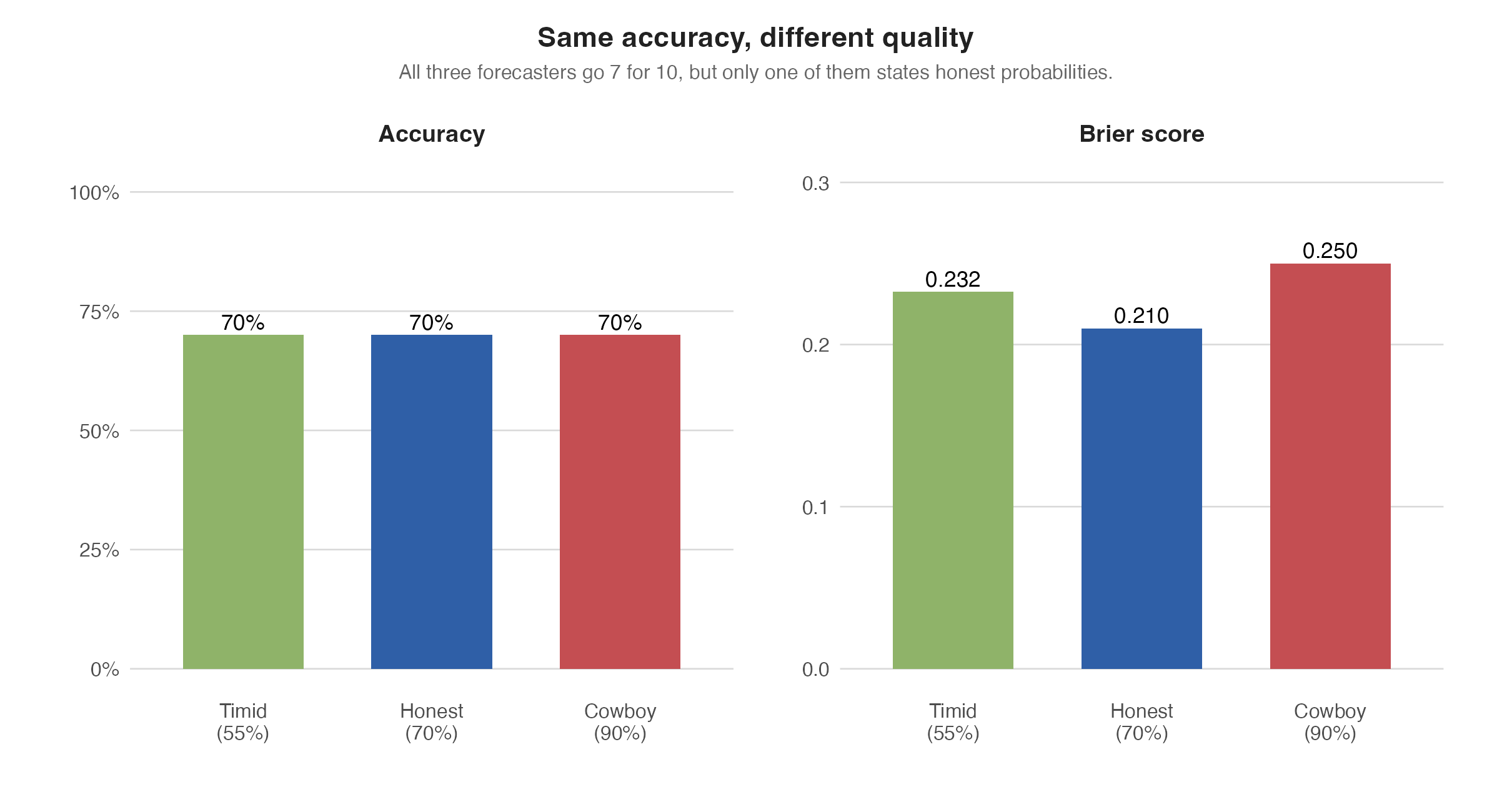
Same accuracy, very different forecasting skill
Here is a toy example with three forecasters who all go 7-for-10:
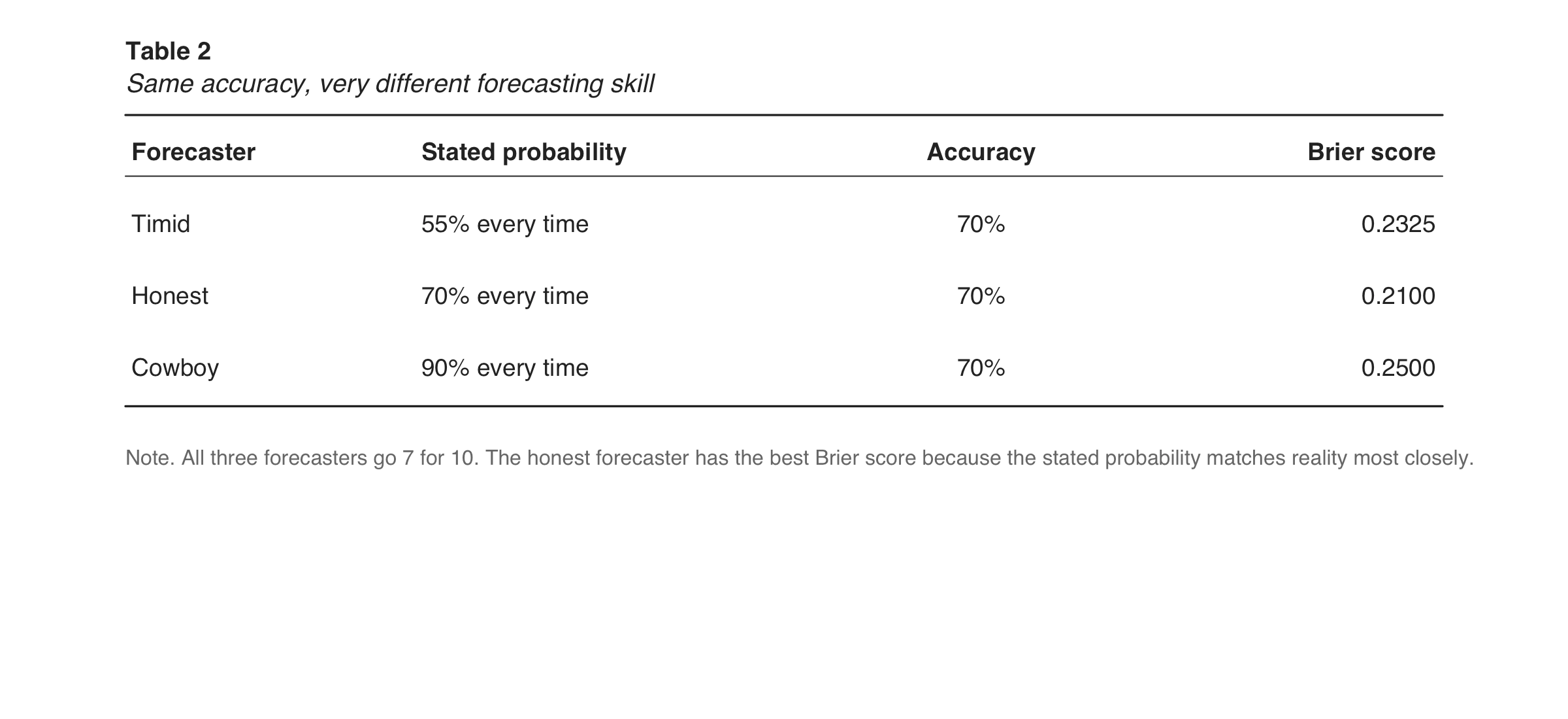
Accuracy sees a three-way tie.
Brier sees what actually happened:
the honest forecaster was best
the timid forecaster was decent but too cautious
the cowboy was worst because the confidence level was fake
That is a much better summary of forecasting quality.
Why this matters in sports
In sports, probabilities are the whole game.
A model that says a fighter is 52% to win and a model that says 82% are not making the same recommendation, even if both technically pick the same side.
That is exactly why this matters for MMA Fight Advisor. If we are going to publish probabilities, those numbers need to do more than point to the right side. They need to tell readers how much confidence that side actually deserves.
Those numbers affect:
how surprised you should be by an upset
how much edge you think you have versus the market
how aggressively you would stake anything
whether the forecaster is just guessing the right side or actually getting the confidence level right too
Accuracy erases all of that. Brier keeps it.
That is why a probability metric is usually more useful than a pick metric for betting models, Elo systems, and weather forecasts.
Brier is really a calibration score in disguise
The cleanest way to think about calibration is this:
Among all your
70%forecasts, about70%of them should happenAmong all your
30%forecasts, about30%of them should happen
When that relationship holds, your model is telling the truth about uncertainty.
Accuracy can miss this completely. A model can be overconfident for years and still look decent on accuracy if it keeps landing on the right side of 50% often enough.
The Brier score notices much earlier, because it cares about the distance between the forecasted probability and reality on every single prediction.
The quickest intuition cheat sheet
If you only remember a few landmarks, remember these:
0.00is perfectAround
0.25means “you are basically living at50%”Big confident misses get ugly fast
Lower is always better, but compare it to baselines and rival models, not to some universal magic cutoff

Closing
Accuracy is still useful if all you want is a pick’em leaderboard.
But if the output is a probability, accuracy is grading the wrong object.
The Brier score asks a better question: were your probabilities any good?
That is why a metric built for weather forecasting in 1950 still feels tailor-made for modern sports modeling. It rewards what we actually care about: not just being right sometimes, but being right with the right level of confidence.
For MMA Fight Advisor, that is the standard that matters. Not just “did we land the side?” but “were we honest about how confident we should have been?”